The goal of this article is to go through the process of seeding data into development environments on Qovery. Seeding the data into dev environments may help you set up clean development environments and thus speed up the development lifecycle in your team. It can be extremely useful for cloning and creating new environments or using the Preview Environment feature on Qovery.
In this guide, we’ll use a Node.js backend and Postgres database.
Seeding SQL
In the first step, let’s create an idempotent script that will seed our development databases. During the development process, we should expect that the state of the database will be synced with the content of this script.
DROP TABLE IF EXISTS _USER;CREATE TABLE _USER(ID INT PRIMARY KEY NOT NULL,FIRST_NAME VARCHAR(255) NOT NULL,LAST_NAME VARCHAR(50) NOT NULL);INSERT INTO _USER (ID, FIRST_NAME, LAST_NAME)VALUES (1, 'John', 'Doe');INSERT INTO _USER (ID, FIRST_NAME, LAST_NAME)VALUES (2, 'Alice', 'Wonderland');
The example above contains only a single table - the SQL script is specific to your application, so you’ll have to create your own that reflects the schema and database state you would expect in the dev environment.
Keep in mind that the script should be idempotent as there are chances it will be executed more than once against a single database during your development process.
Migration Script
In the next step, we’ll create a script that will be used to connect to the database and seed the data.
const fs = require('fs')const { Pool } = require('pg')require("dotenv").config()const databaseUrl = process.env.DATABASE_URL || 'postgresql://localhost:5432/test';const pool = new Pool({connectionString: databaseUrl,})if (process.env.NODE_ENV !== 'production') {const seedQuery = fs.readFileSync('db/seeding.sql', { encoding: 'utf8' })pool.query(seedQuery, (err, res) => {console.log(err, res)console.log('Seeding Completed!')pool.end()})}
The script connects to our Postgres instance, reads the seeding SQL, and makes the required updates. It does it only for non-prod environments thanks to the NODE_ENV environment variable.
To make our life easier, we can declare the seeding command in our package.json:
..."seed": "node db/index.js"...
Seeding
To seed the data, we’ll use ENTRYPOINT in our Dockerfile. For more details, you can read our guide.
FROM node:16# Create app directoryWORKDIR /usr/src/app# Install app dependencies# A wildcard is used to ensure both package.json AND package-lock.json are copied# where available (npm@5+)COPY package*.json ./RUN npm install# If you are building your code for production# RUN npm ci --only=production# Bundle app sourceCOPY . .EXPOSE 3000ENTRYPOINT ["./entrypoint.sh"]CMD [ "node", "bin/www" ]
Add entrypoint.sh file to be executed on each environment where the app container runs:
#! /bin/shnode db/index.js# Execute the given or default command:exec "$@"
Example
The following examples will show the application of seeding the data in dev environments after cloning an environment and using the Preview Environment feature.
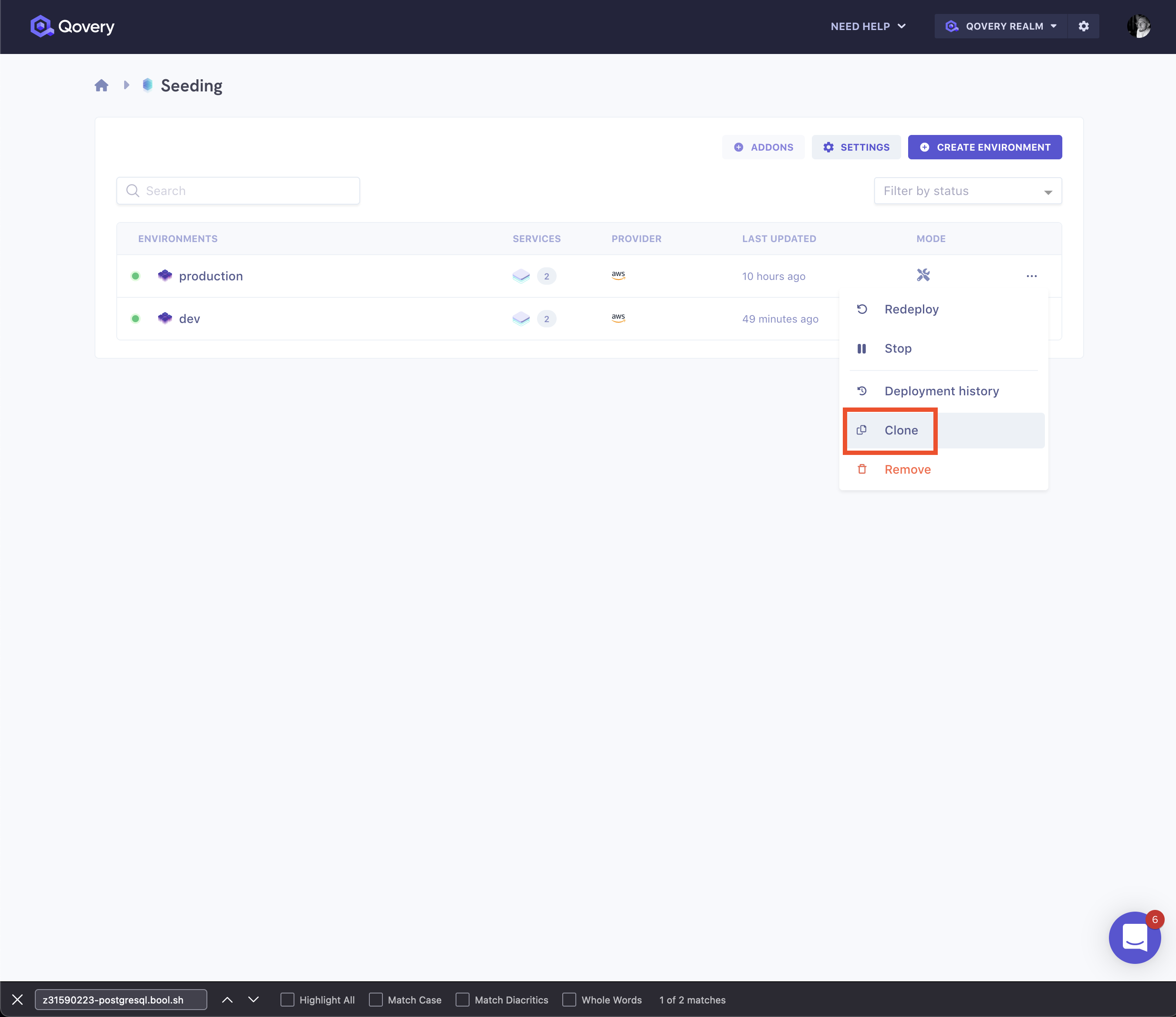
Clone Environment
Clone environment feature allows you to make a complete clone of a chosen environment, including its all applications, services, and their configs. In the example we will clone a new environment and have our seed data injected automatically.
First, we make a clone of our production environment:
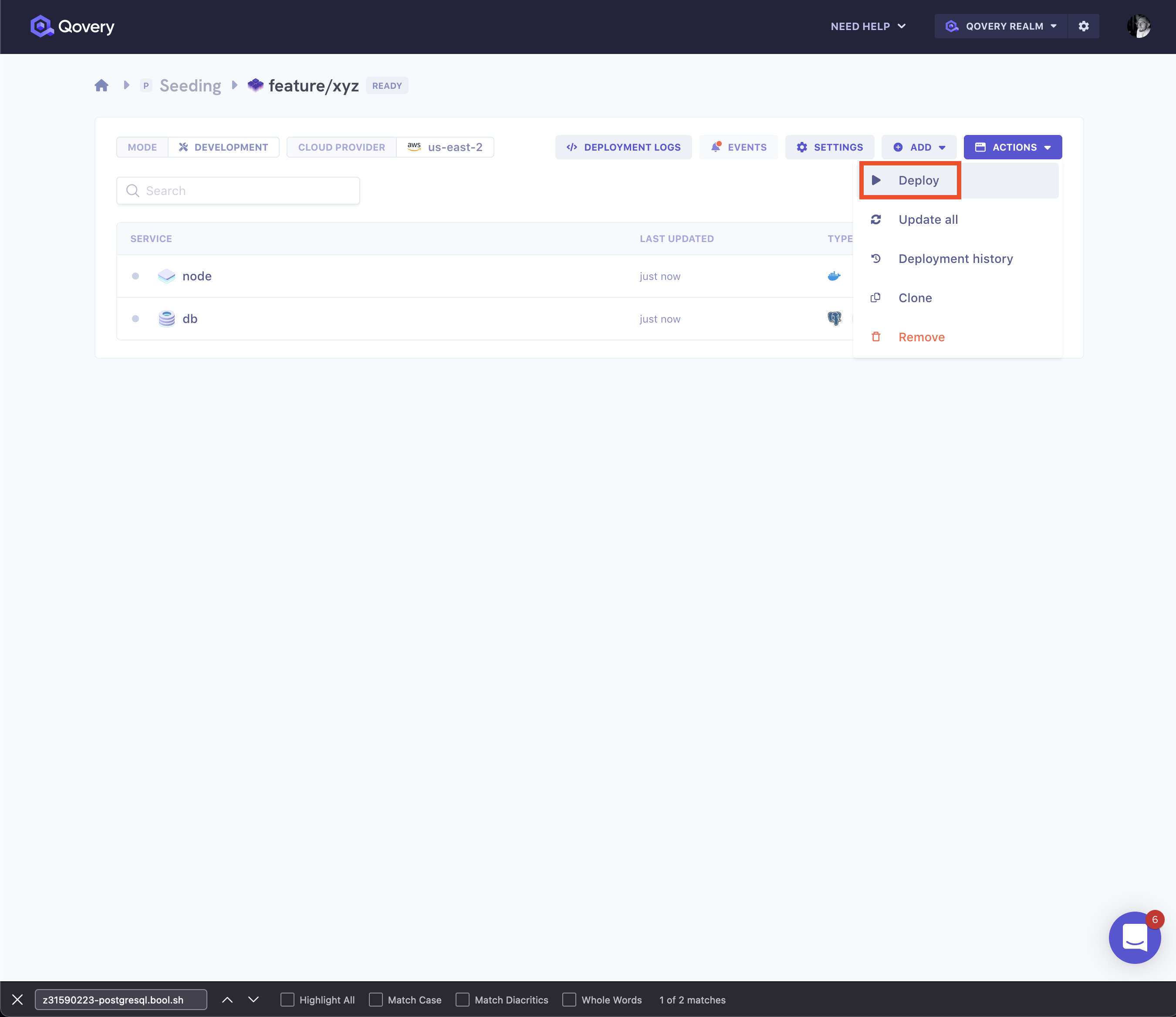
Then, we deploy the new environment:
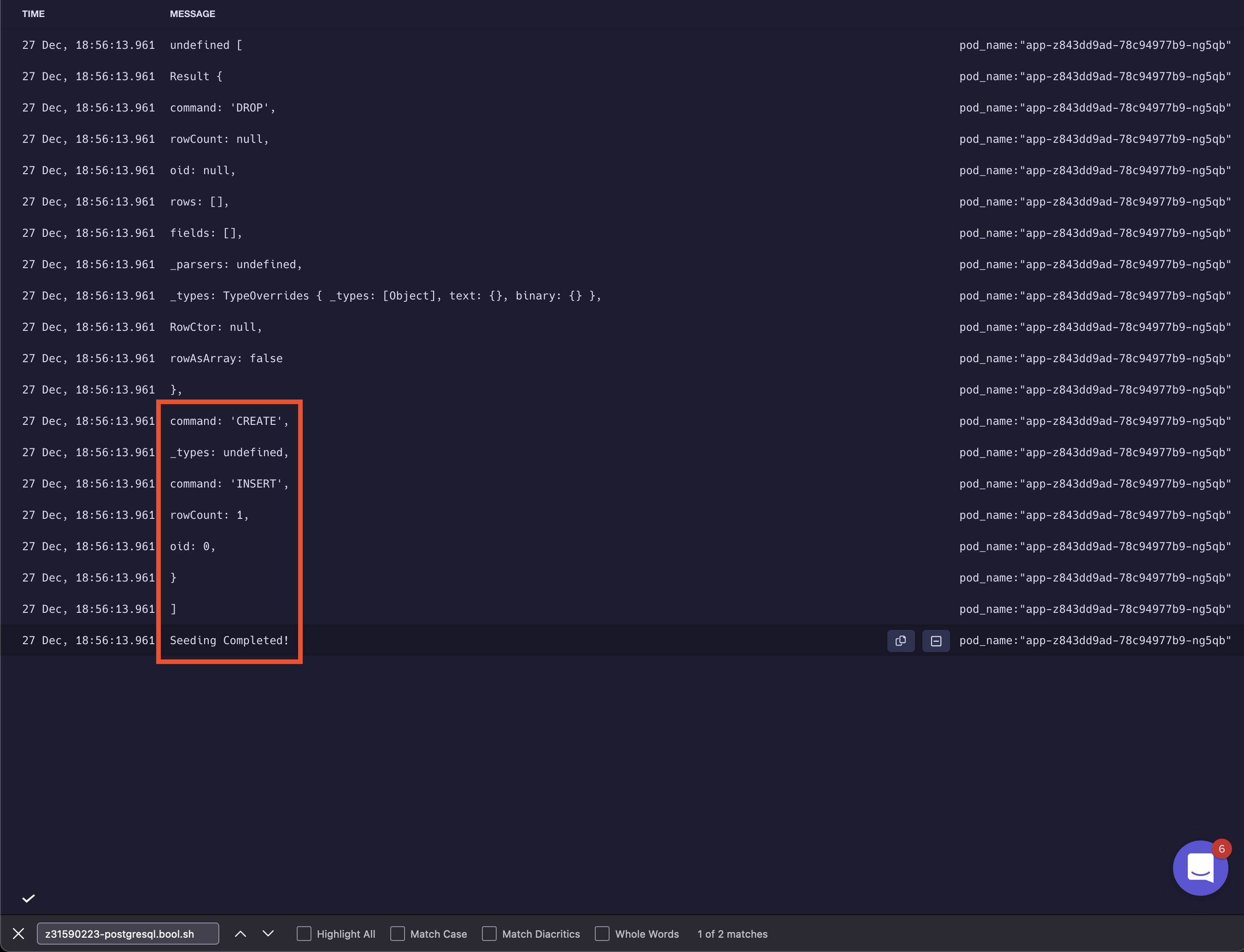
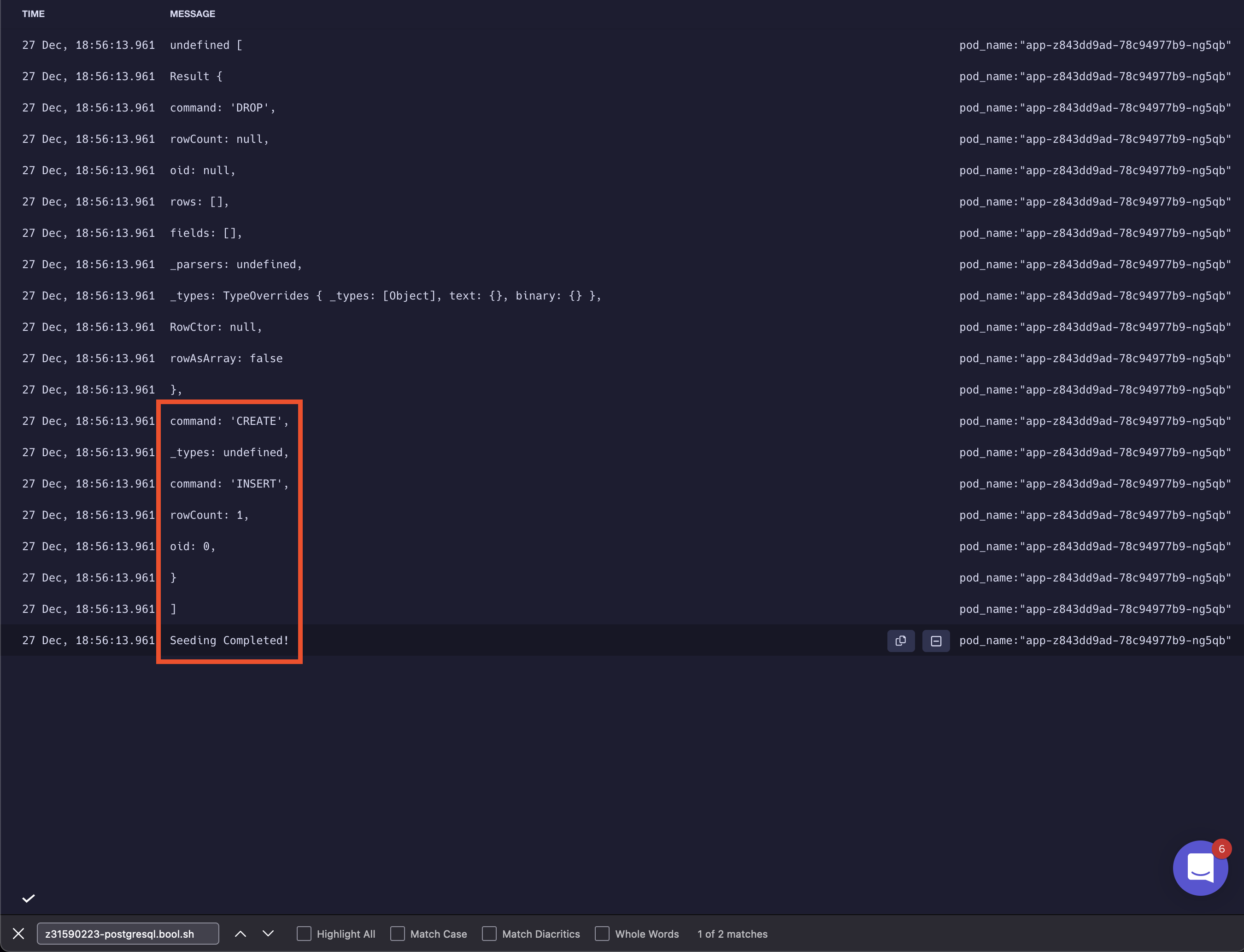
After navigating to deployment logs, we will notice our seed data inserts logged:
Preview Environment
Preview Environment feature allows you to automatically create new development environments to validate new changes before merging them to your production branch.
First, we open a pull request:
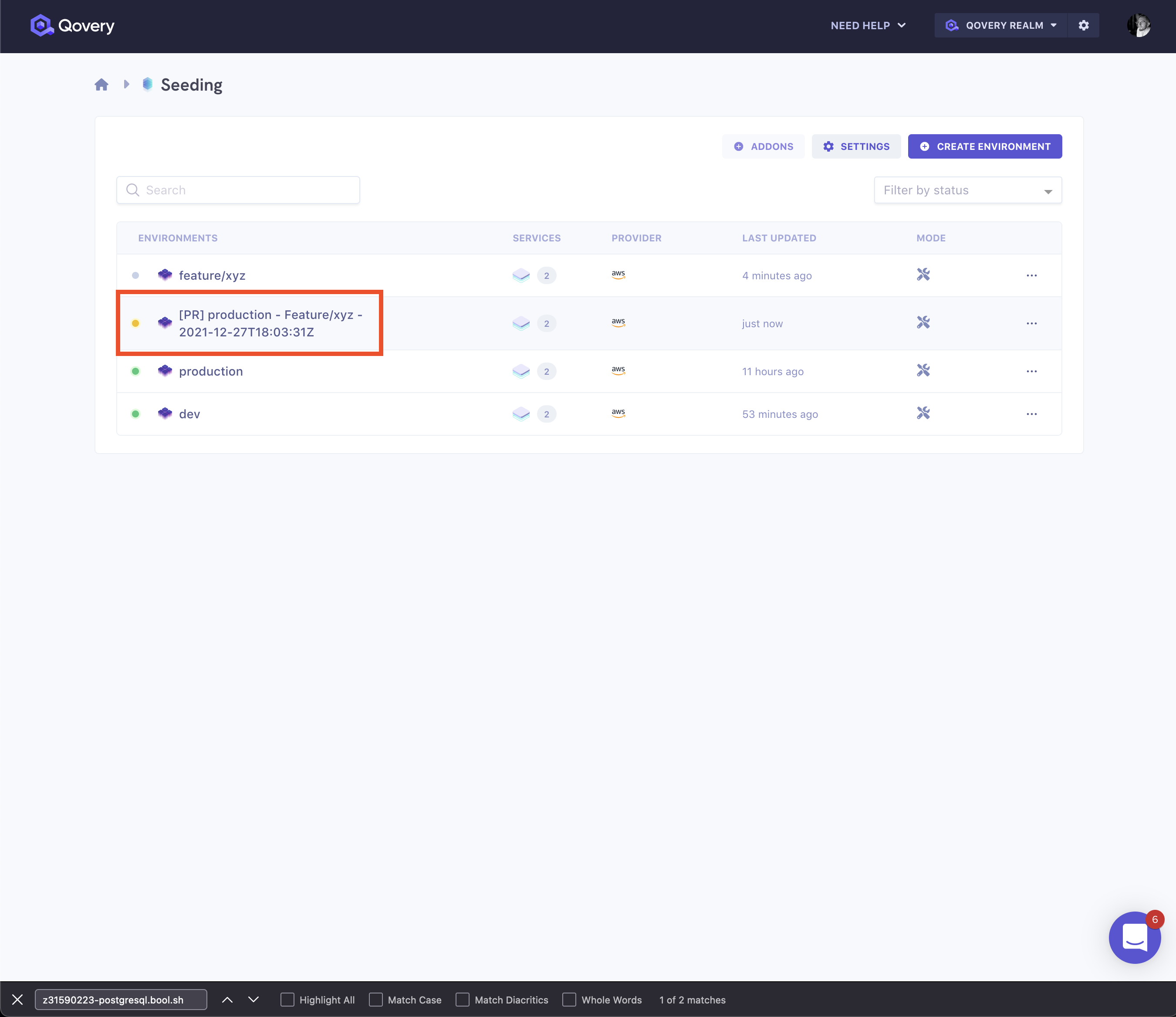
Then, in list of environments, we get a new environment automatically created for the pull request:
When you open the logs of the deployment, you’ll see the seed data injection logs: