Lifecycle Job
Before you begin, this documentation assumes the following:
You have created an Environment.
A Lifecycle Job is a job that runs on your kubernetes cluster with the following characteristics:
- it is executed ONLY when the selected event (deploy/stop/delete) occurs (unless its execution is forced, see the Force execution section).
- any output file created at the end of the execution will be automatically injected as environment variable to any service within the same environment (see the Job Output section).
Given its characteristics, lifecycle jobs are particularly useful for:
- Seed your database on your preview environment: you can create a custom job that will seed a database when the preview environment is deployed
- Create an external resources not natively managed by Qovery: you can create a custom job that will create the external resource. By writing the connection strings in an output file, those information will be injected as environment variables on any service of the environment (so that they can consume this new resource).
The execution of this job follows this flow:
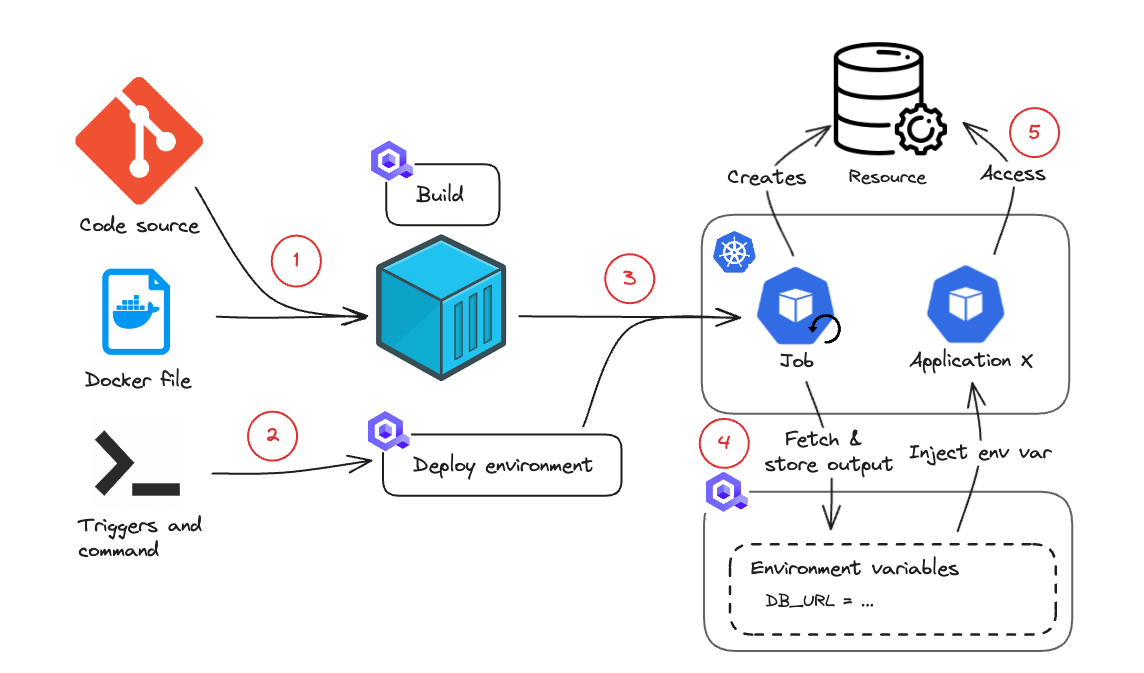
- You define the repository where the code is located and the Dockerfile to be used to containerize the application (deploying from a container registry is supported as well)
- You define the triggers and the command to be executed when your code runs. For example: "on start", execute "start.sh"
- When an event happens on your environment or job, if the event matches your trigger condition, the job is deployed and scheduled for execution.
- The job is executed on your cluster and can interact with some external services. For example, it can use a Terraform manifest to deploy an RDS instance.
- If the job creates an output in a specific format (see Job output section), this can be retrieved and injected as environment variable for any other service within the environment. For example, you can retrieve the RDS DB URI so that the other applications can use it.
A lifecycle job can be executed on the following environment/job events:
- Deploy: the job is executed when the environment/job is deployed. Note that this includes both the "Deploy" and "Redeploy" actions so you should take care of managing this in your code to avoid executing it twice (on the first deploy and on the re-deploy).
- Stop: the job is executed when the environment/job stops.
- Delete: the job is executed when the environment/job is deleted.
Qovery allows you to create and deploy jobs from two different sources: Git Repository or Container Registry
Deploying from a Git Repository
In this configuration, Qovery will pull the code from the chosen repository, build the application and deploy it on your kubernetes cluster.
The list of Git repositories available during the setup is strictly tied to the permissions of your git account (by default Qovery can access all your repositories). You can also manage the access via dedicated Git Tokens.
Deploying from a Container Registry
In this configuration, Qovery will pull the chosen image and deploy it on your kubernetes cluster.
To improve the security and avoid deploying images from non-authorized registries, we have decided to restrict the list of Container Registry you can use during the setup process. Only an administrator with the right permissions can manage it from the Container Registry Management page
Create a Job
Go into the chosen environment and press the "New Service" button and then the "Create Lifecycle job" button
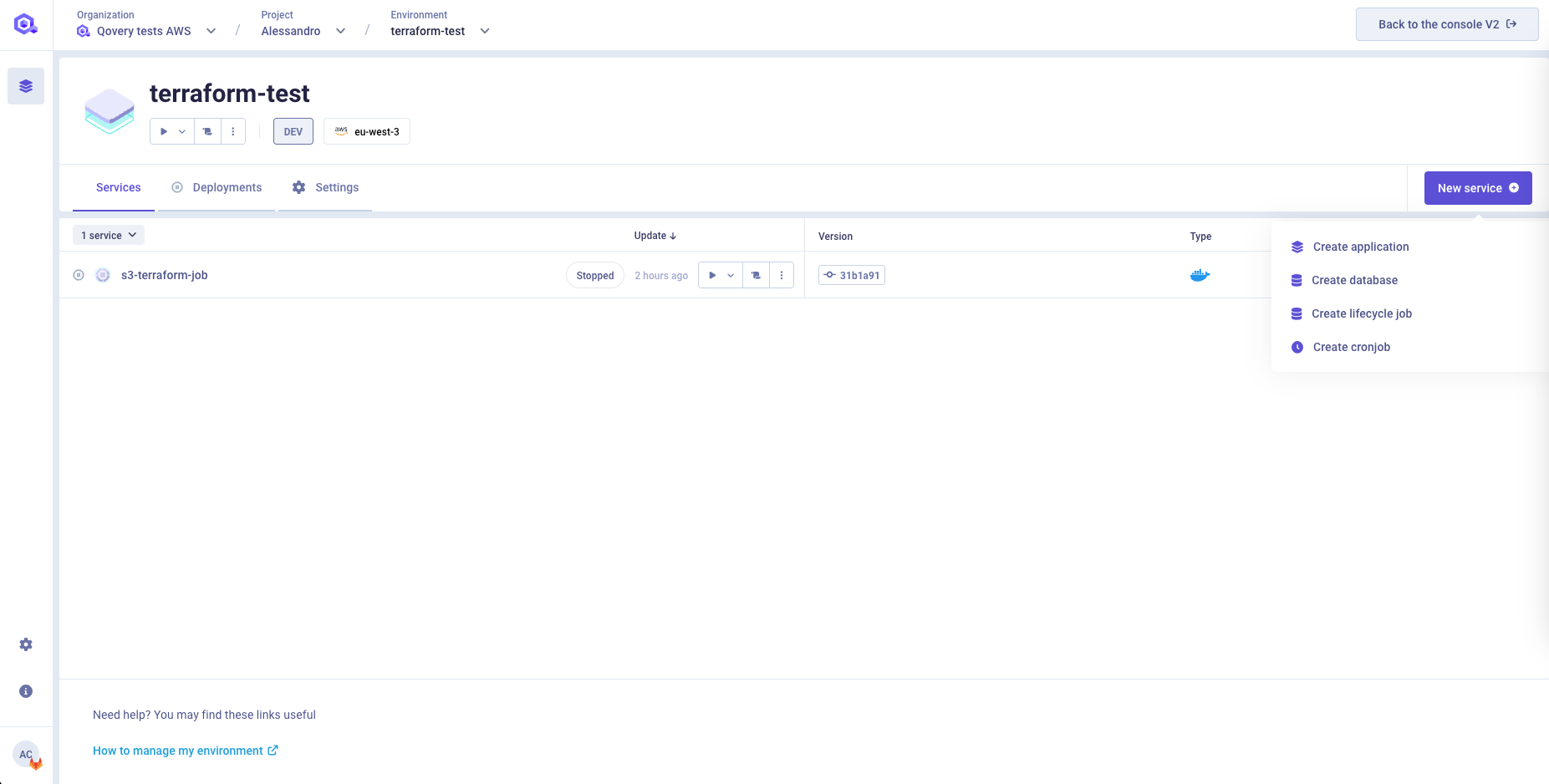
Select the following fields:
- Name: give a name to your application
- Source: Chose between Git Repository or Container Registry, depending on the source location of your application
If you want to deploy a cronjob from a Git Repository you will have to select:
- Git Repository: Select the git provider hosting your code (it can be hosted on GitHub, GitLab or Bitbucket). You can add a new git access by clicking on
New git access. - Branch: Select branch that Qovery should use to deploy your code
- Root Application Path: base folder in which the code resides in your repository
If you want to deploy a job from a Container Registry you will have to select:
- Registry: select the container registry storing the image of your job.You can add a new container registry by clicking on
New registry. - Image name: the name of the image to be deployed with this job (example: postgres)
- Image tag: the tag of the image to be deployed with this job (example: 12)
Auto Deploy
See the Deploying with auto-deploy feature section.
Extra labels/annotations (optional)
Add your extra annotation/label groups. See the Add annotation/label group section for more information.
- Specify the Dockerfile
See the Dockerfile section for more information.
- Specify the triggers
See the Triggers section for more information.
- Within this section, you will need to define the resources to be assigned to your job at run time.
- vCPU: the vCPU assigned to each instance of your application. The default is 500m (0.5 vCPU).
- RAM: the amount of RAM assigned to each instance of your application. The default is 512MB.
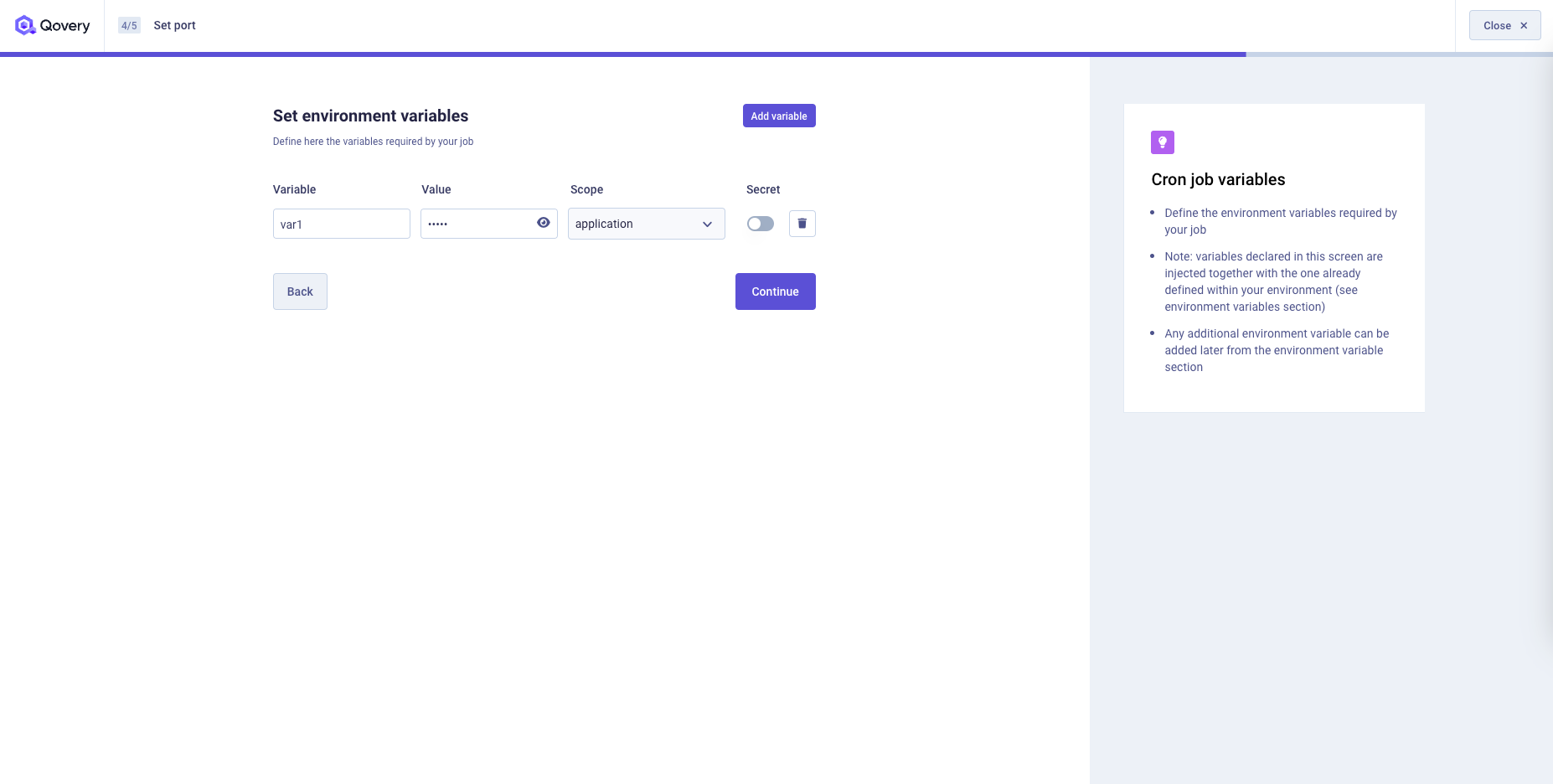
Define any input variable required by your job to run. Any declared variable will be injected as environment variables based on the selected scope (project, environment, service) Any additional environment variable can be added later from the environment variable section
You will find a recap of your job setup and you can now decide to: 1. Go back to one of the previous steps and change your settings 2. Create your job without deploying it 3. Create and deploy your job
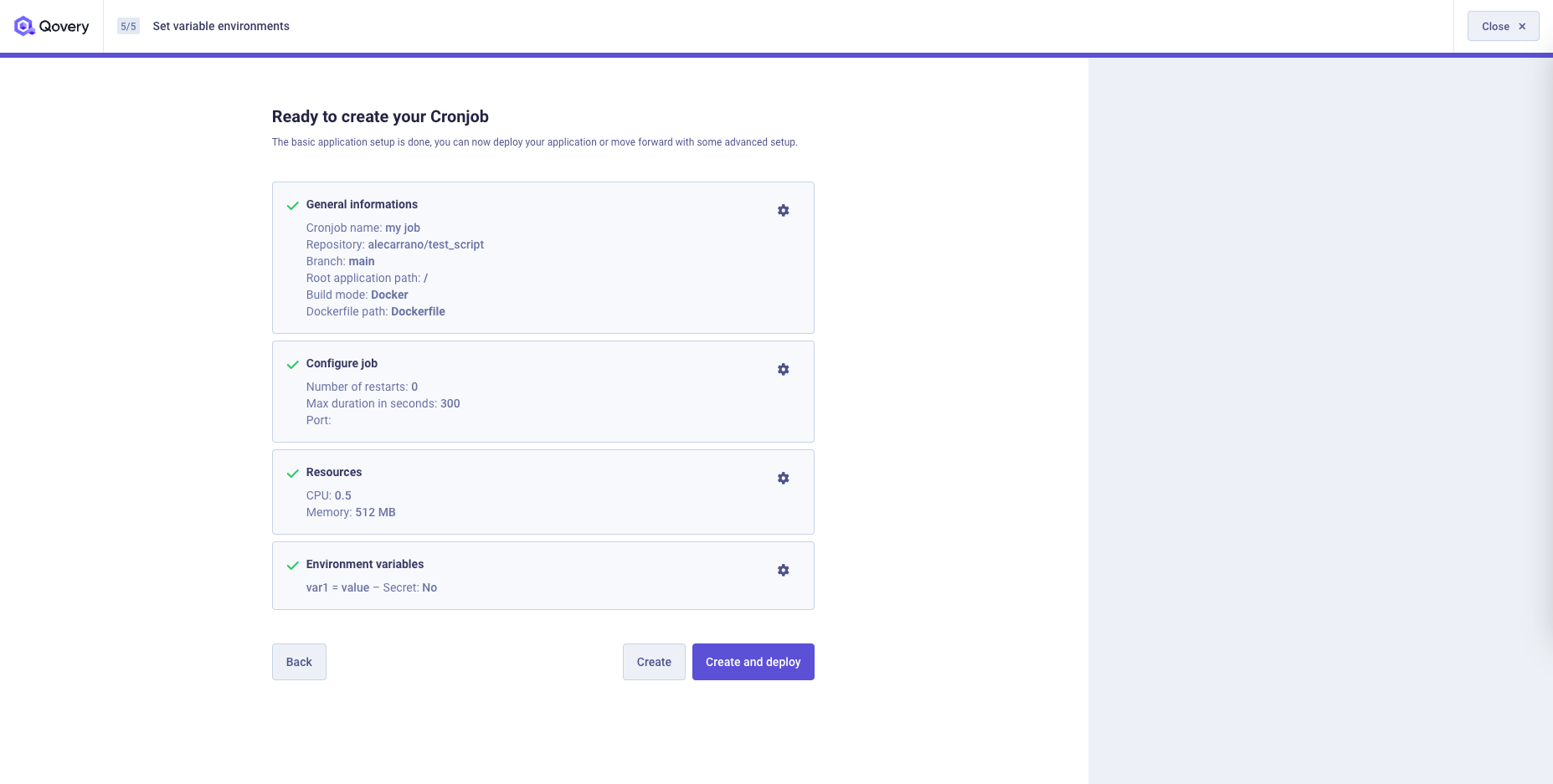
Deployment Management
Have a look at the Deployment Management section for more information.
Job output
Qovery expects the output file to be written in the following path /qovery-output/qovery-output.json (the output folder is automatically mounted by Qovery).
The file should follow this format:
{"varname1": {"sensitive": true,"value": "myvalue"},"varname2": {"sensitive": false,"value": "myvalue"}}...
At the end of the job execution, this file will be processed by Qovery and a set of environment variables will be created, one for each element in the json. The information in the json file will be mapped to an environment variables in this way:
- Variable Name:
QOVERY_OUTPUT_JOB_<JOBID>_<VARNAME>, where<JOBID>is the id of the Job on Qovery side and<VARNAME>is the name of the element in the output file. - Variable Value: field "value"
- Secret: field "sensitive"
An alias <VARNAME> will be automatically created to simplify your setup.
The output (and thus the created environment variables) are displayed in the Lifecycle job overview.
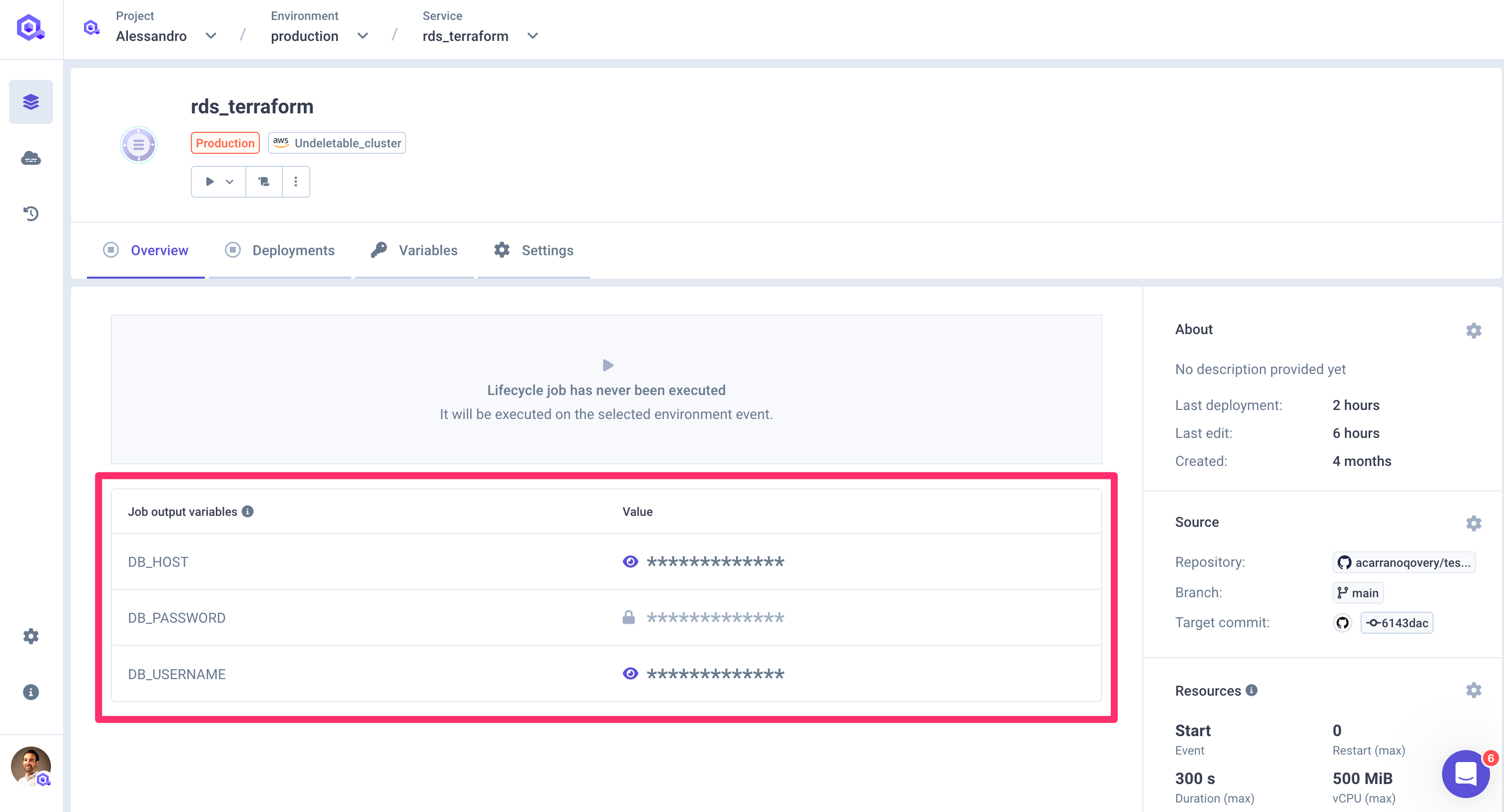
Example
Let's say that the code of our job creates a PostgreSQL RDS on AWS. At the end of its execution, the job should know the connection Once created, the job should know the connection string of the PostgreSQL. The job can now create a file /qovery-output/qovery-output.json with the following structure:
{"POSTGRES_DB_HOST": {"sensitive": False,"value": "zf138d9c8-postgresql"},"POSTGRES_DB_USER": {"sensitive": False,"value": "root"},"POSTGRES_DB_PASS": {"sensitive": True,"value": "mypassword"},"POSTGRES_DB_TABLE": {"sensitive": False,"value": "MYDB"},"POSTGRES_DB_PORT": {"sensitive": False,"value": "3600"}}
This file will be processed by Qovery and the following environment variables will be created:
Var QOVERY_OUTPUT_JOB_<JOBID>_POSTGRES_DB_HOST
- Value: "zf138d9c8-postgresql"
- Secret: false
- Alias: POSTGRES_DB_HOST
Var QOVERY_OUTPUT_JOB_<JOBID>_POSTGRES_DB_USER
- Value: "root"
- Secret: false
- Alias: POSTGRES_DB_USER
Var QOVERY_OUTPUT_JOB_<JOBID>_POSTGRES_DB_PASS
- Value: "mypassword"
- Secret: true
- Alias: POSTGRES_DB_PASS
Var QOVERY_OUTPUT_JOB_<JOBID>_POSTGRES_DB_TABLE
- Value: "MYDB"
- Secret: false
- Alias: POSTGRES_DB_TABLE
Var QOVERY_OUTPUT_JOB_<JOBID>_DB_PORT
- Value: "3600"
- Secret: false
- Alias: POSTGRES_DB_PORT
Once the execution of the job is terminated and the environment variables are created, any application within the same environment will be able to access those environment variables and thus connect to the postgres instance.
Force Run
You can force the execution of a job independently its deployment status by:
Select the job that you want to force
click on the
Playbutton of the cronjob you want to force and select theForce Runoption. Note: the same option is available on the service list as wellSelect the environment event you want to force.
Once you click, the job will be deployed and executed with the entrypoint and arguments associated to the selected event. You will be able to follow its execution within the application logs
Configuration
Once created, you can access the configuration at any time via the Settings tab available on the service section
You can find below the description of each of the tabs available in this section
General
General settings section allows you to set up your application name and the source code location (git repository or image registry) .
Git Repository
If your job is built and deployed from a git repository, within this section you can:
- Modify the git provider where your code is stored (it can be hosted on GitHub, GitLab or Bitbucket).
- Modify the branch that Qovery should use for deploying your code
- Modify
Root Application Path- base folder in which the application resides in your repository
Container Registry
If your application is deployed from an image registry, within this section you can modify:
- Registry: select the container registry storing the image of your application. Note: only pre-configured registry are available in this list, check the Container Registry Management page for more information.
- Image name: the name of the image to be deployed with this application (example: postgres)
- Image tag: the tag of the image to be deployed with this application (example: 12)
Auto Deploy
See the Deploying with auto-deploy feature section.
Extra labels/annotations (optional)
Add your extra annotation/label groups. See the Add annotation/label group section for more information.
Dockerfile
If your job is built via the Qovery CI (Source="Git Repository"), this section allows you to define the Dockerfile location.
Two options are available, depending on where you want to store the Dockerfile:
Git repository
Specify the location of your Dockerfile in Dockefile path field.
Dockerfile stage: if you have a multistage dockerfile, select the target stage to build. Filling this field is equivalent to running the command docker build --target <selected_stage> (field available only if the application built by the Qovery CI)
RAW Dockerfile
Qovery can store and inject for you the Dockerfile instead of storing it into your repository.
If you don't have one, you can use the docker init command to generate one for your application (check the documentation here).
Triggers
This section allows you to define when the lifecycle job should be executed and which command should run.
In this section you can configure:
- Event: select the environment/job event which should trigger the execution of the job (deploy, stop, delete)
- Image Entrypoint: the entrypoint to be used to launch your job (not mandatory).
- CMD Arguments: the arguments to be passed to launch your application (not mandatory) separated with a space. Example:
rails -h 0.0.0.0 -p 8080 string "complex arg". - Number of restarts: Maximum number of restarts allowed in case of job failure (0 means no failure)
- Max duration time in seconds: Maximum duration allowed for the job to run before killing it and mark it as failed
- Port: Port used by Kubernetes to run readiness and liveliness probes checks. The port will not be exposed externally
Resources
CPU
To configure the number of CPUs that your job needs, adjust the setting in the Resources section.
Please note that in this section you configure the CPU allocated by the cluster for your application and that cannot consume more than this value. Even if the application is underused and consume less resources, the cluster will still reserve the selected amount of CPU.
RAM
To configure the amount of RAM that your app needs, adjust the setting in Resources section.
Please note that in this section you configure the CPU allocated by the cluster for your application and that cannot consume more than this value. Even if the application is underused and consume less resources, the cluster will still reserve the selected amount of CPU. If your application requires more RAM than requested, it will be killed by the kubernetes scheduler.
Deployment Restrictions
This section allows to specify which changes on your repository should trigger an auto-deploy (if enabled). To know more about how to configure your Deployment Restrictions, have a look at the deployment restrictions section.
Advanced Settings
You can further customize the service behaviour via the service advanced settings. Check this documentation to know more.
Environment Variable
To learn how to set up environment variables in your projects and applications, navigate to configuring Environment Variables section.
Secrets
To learn how to set up secrets in your projects and applications, navigate to configuring Secrets section.
Logs
To learn how to display your application logs, navigate to logs section
Clone
You can create a clone of the service via the clone feature. A new service with the same configuration (see below for exceptions) will be created into the target environment.
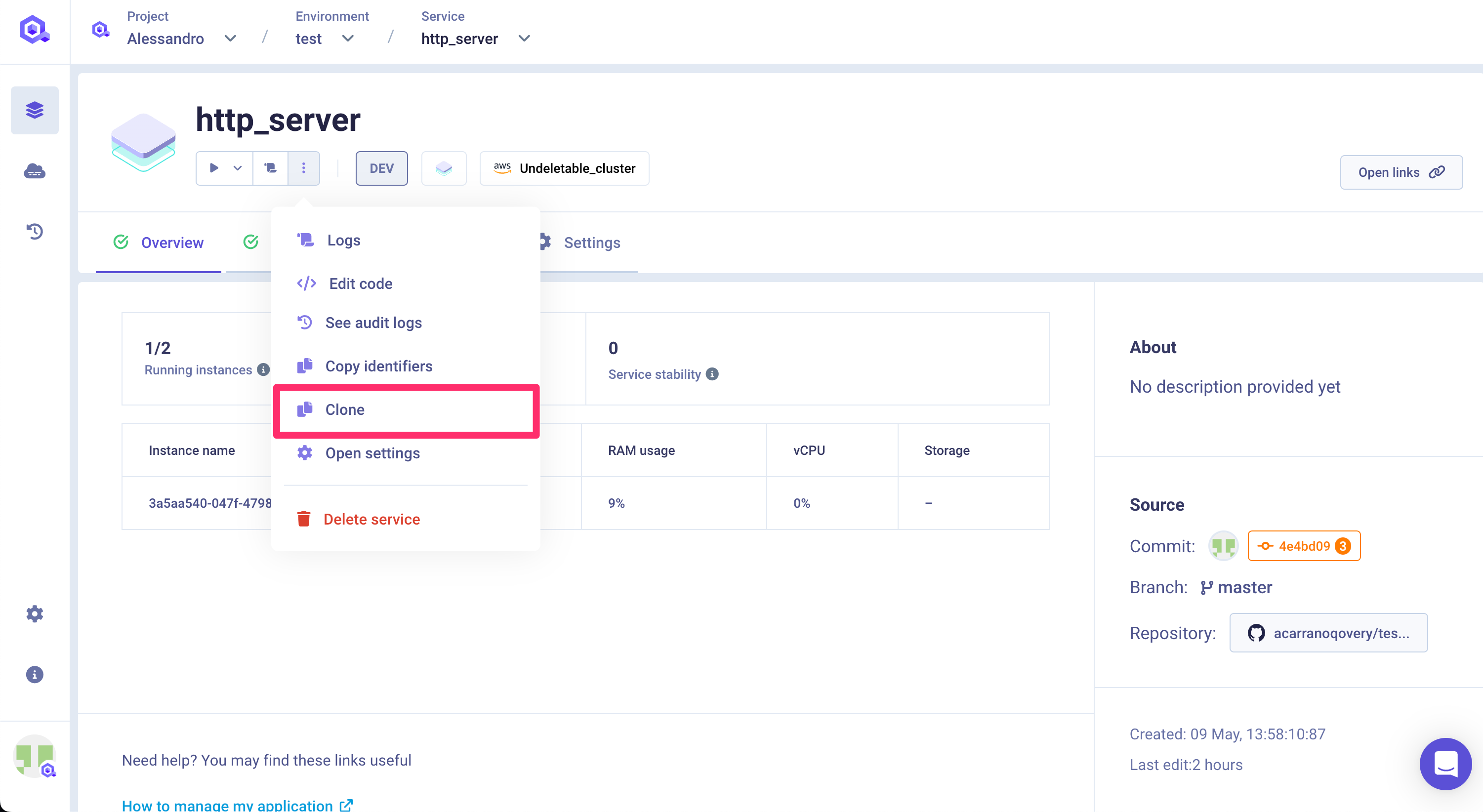
The target environment can be the same as the current environment or even another one in a completely different project.
Important information
Not every configuration parameter will be copied within the new service for consistency reasons. The configuration is fully or partially copied depending on the target environment:
- same environment:
- custom domain: this setup is not copied into the new service (to avoid collision)
- another environment:
- custom domain: this setup is not copied into the new service (to avoid collision)
- environment variable: aliases defined on environment variables are not copied (since the aliased env var might not exist)
- deployment pipeline: stage setup is not copied (since the target stage might not exist)
- number of instances: if the target environment runs on a Qovery EC2 cluster, the max number of instances is set to 1 (Qovery EC2 constraint)
Please check the configuration of the new service before deploying it.
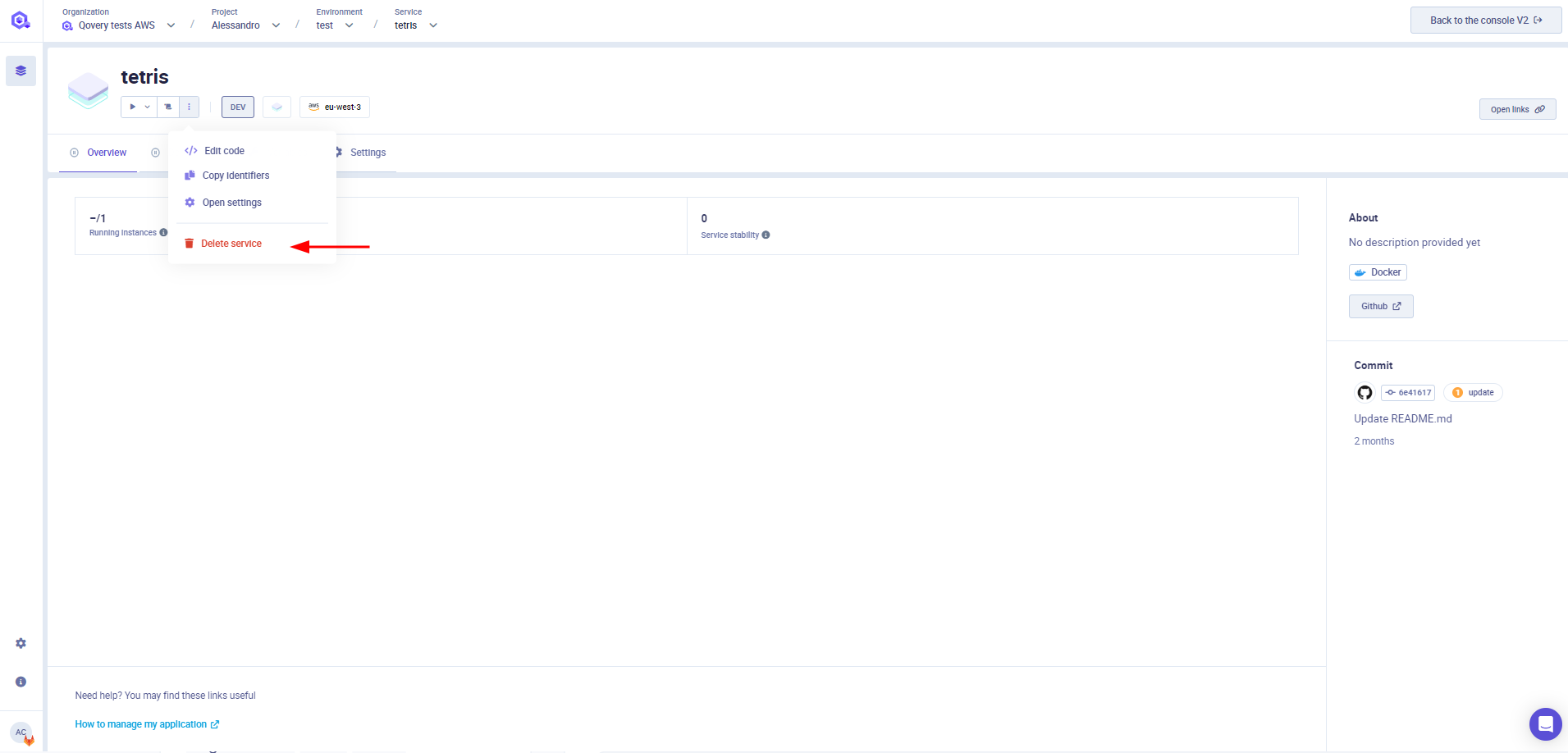
Delete a job
Select the job you want to delete
In the overview, click on the
3 dotsbutton and remove the job. Note: the same option is available on the service list as well